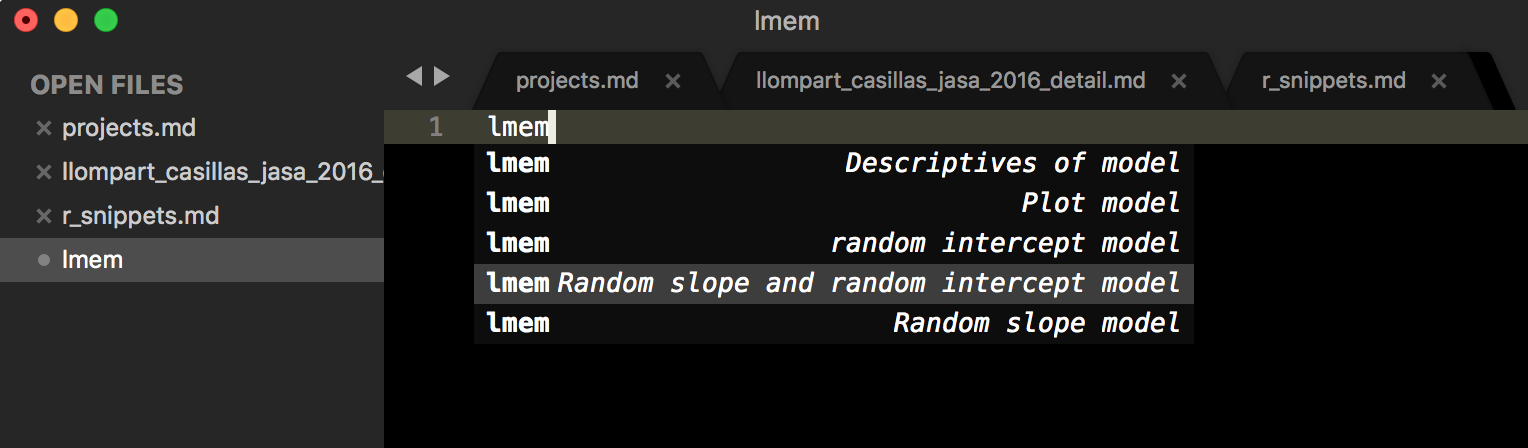
This repository is a collection of snippets that I use in SublimeText for doing statistical analysis in R. The goal is straightforward: document the code that I use most often while doing linguistic research and make it readily available (and understandable) to other linguists. If you are interested in helping see the github repository. To install R-snippets see the package control page. To use a snippet, type the trigger and hit the tab key. For example, typing lm brings up the following window:
Selecting Random slope and random intercept model expands to…
# load lme4 for mixed models
library(lme4)
# random intercept and random slope model
modelName = lmer(DV ~ fixedFactor1 +* fixedFactor2 + (1 + randomSlope|randomInt), data=df)
modelName
hist(residuals(modelName))
qqnorm(residuals(modelName))
qqline(residuals(modelName))Main triggers:
- “plot”: templates for plotting in base R
- “edit”: options useful for data cleansing and saving
- “desc”: descriptive statistics of data
- “ttest”: distinct types of t-test
- “aov”: distinct analysis of variance models
- “lm”: linear and logistic regression
- “lmem”: linear mixed effects models
Extras:
- “subset”: make subsets of a DF
- “read”: read/load/install data/packages into R
- “save”: save plots, dfs, tables, etc.
- “tikz”: template for creating R plots in LaTeX